Here’s a simple chart that shows the hierarchy of the various number-related type classes in Haskell. Also shown are the methods required for a minimal complete definition. (Click to zoom in!)
You can also get the SVG version.
{kind=link}
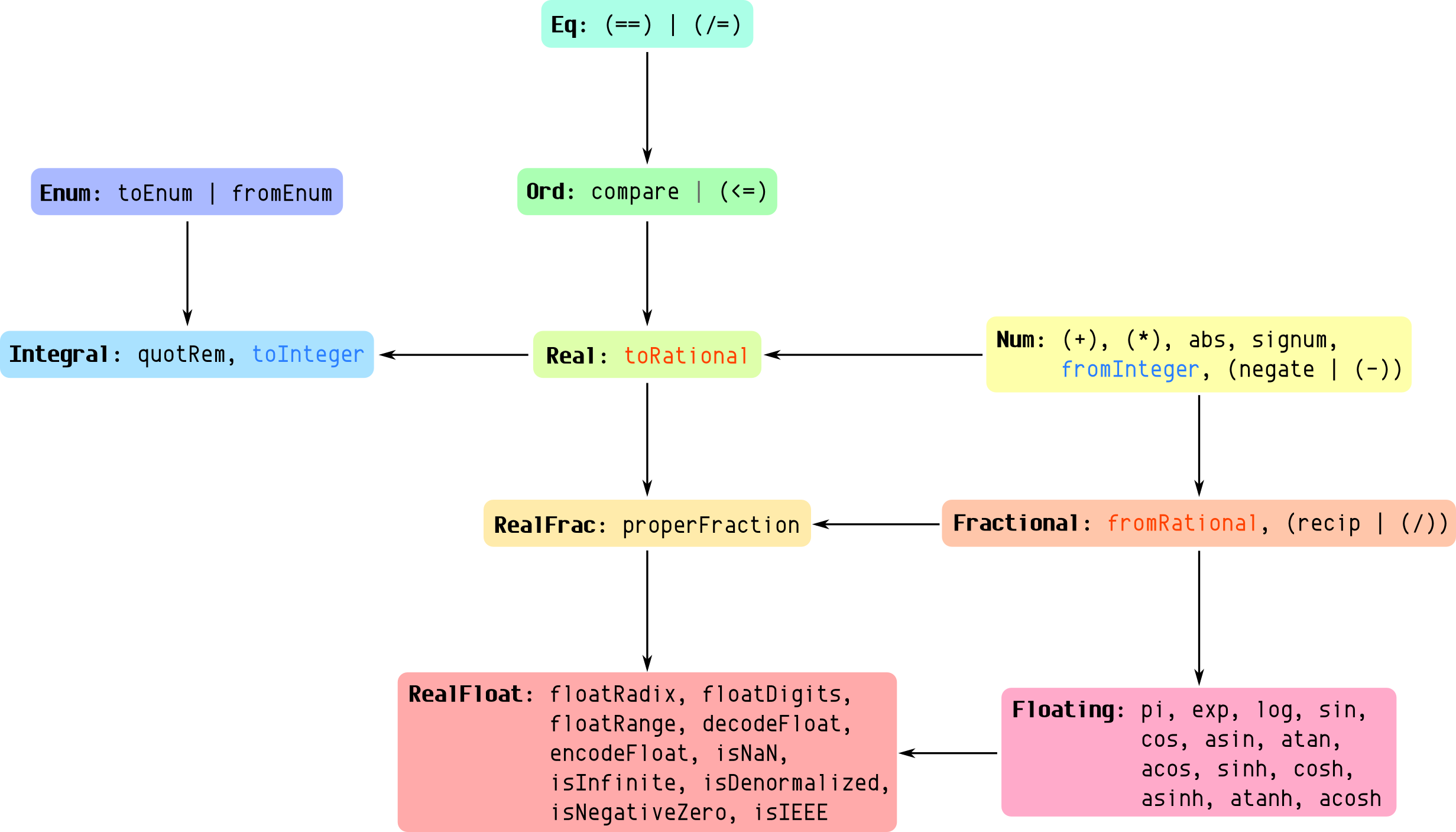
Here’s a simple chart that shows the hierarchy of the various number-related type classes in Haskell. Also shown are the methods required for a minimal complete definition. (Click to zoom in!)
You can also get the SVG version.
Previously, I ran into an issue with pasting non-ASCII characters into Emacs on my Windows system. For example, copying a Greek small letter rho (ρ) would result in a question mark (?) appearing in the Emacs editor. Oddly enough, copying Unicode characters from Emacs generally worked fine.
Originally, I assumed it was a bug in Emacs. Yet, I couldn’t find any bug reports about it so that seemed unlikely. Eventually, I came to realize that one of the settings in my Emacs profile (.emacs or init.el) caused the problem:
(set-selection-coding-system 'utf-8) ; wrongAs it turns out, the correct value is 'utf-16-le because the Windows API is built entirely on top of UTF-16:
(set-selection-coding-system 'utf-16-le) ; correctThe problem was introduced a while back: it was part of a hack to force Emacs to use UTF-8 as the default buffer encoding. At the time, I copied the code from this StackOverflow answer (fixed now) without too much thought, not realizing it would cause a bug discovered several months later. It turns out that set-selection-coding-system and set-clipboard-coding-system actually do the same thing, but the connection between selections and clipboards is not exactly obvious until one becomes familiar with the Emacs jargon.
Fortunately, the choice of the selection-coding-system doesn’t affect the encoding of the buffer itself, so it doesn’t invalidate the hack I used to enforce UTF-8 as the default buffer encoding.
This story does not have a happy ending. Rather, it explores the various difficulties I encountered while trying to customize Cabal’s build process.
The default setup of Cabal generally works fine … as long as you’re not doing anything unusual. What I needed to do was to try and find some platform-dependent C libraries and also do a little bit of custom preprocessing on the source code. Cabal’s way of finding C libraries is not very sophisticated and it only supports a limited number of known preprocessors (such as C2HS), so I had to cook up the solution myself.
The “Custom” build type provided by Cabal is very powerful, since you are given full control of the Cabal library. All you have to do is to edit your *.cabal file to say
build-type: Customand then homebrew your own Setup.hs. Sounds simple, right?
Unfortunately, it’s not so easy because there just isn’t a whole lot of documentation about writing custom Cabal builds. The User Guide doesn’t say much about it other than mentioning the flag and ending with an ominous “Good luck”. And there’s about one example on StackOverflow.
I mean, at least the official documentation for the Cabal library isn’t bad, but it’s so overwhelming that you are sort of left wondering where to even begin.
The example on StackOverflow was helpful for getting started though. It turns out most of the time all you care about is writing hooks. Hooks allow existing Cabal functionality to be overriden by your own functions. The names of the hooks are relatively descriptive, but the argument lists can be somewhat daunting at first because there are quite a few record-like data types used by Cabal. (Records are also somewhat painful to work with in Haskell, especially ones that are heavily nested.)
I’ll use the one that I worked with as an example: the postConf (post-configuration) hook. The others are similar (I hope), but I’ve not actually played with them.
I’m not entirely clear what the docs mean by “after [the] configure command” though! My guess is that it occurs immediately after parsing the *.cabal file and evaluating with the conditionals in the *.cabal file. Why? If you look at confHook instead, you will find that it has GenericPackageDescription instead of PackageDescription. The GenericPackageDescription contains the unevaluated conditionals, and thus you’ll find that the package description is still incomplete (lots of Nothing) if you use confHook instead of postConf.
The arguments are relatively self-explanatory if you examine their types, so I won’t say much about those.
How do you write the hook then? Here’s a basic template:
Simply define a function with the right signature, and then call the default hook after doing whatever you wanted to do in the hook. The default hooks are all conveniently stored in simpleUserHooks.
The main function is straightforward:
So all in all it doesn’t seem too difficult. However, it turns out I didn’t fully understand what the hook does.
The postConf hook is not guaranteed to run if you are building or installing or doing anything else. Furthermore, even if you modify the package description and pass it into the default hook, (due to some weird reasons I’ve yet to figure out) it affects the configuration process but won’t affect the actual build!
So I spent a few hours futilely debugging a problem only to realize the changes I made to postConf didn’t actually affect the build. There is probably a way to make it work though, but it would likely involve binding it to more hooks.
After that “profound” realization, I’ve not really looked into this further. I settled for the simple build type instead because it’s just not worth all the trouble (and I found alternative, simpler solutions). :c